Andyʼs working notes
About these notesRetry intervention produces substantial increases in early accuracy on Quantum Country
In 2021 Q1, I implemented an experiment on Quantum Country which randomly skips the SRS retry mechanism 20% of the time (i.e. each time a question is answered, whether to retry is randomly determined). For these readers, the retry intervention caused a substantial increase in accuracy for forgotten questions in the first two repetitions. Such large improvements with such a simple intervention suggests that there may be quite a lot of low-hanging fruit available.
This is a within-subjects design—i.e. each reader will get the retry behavior sometimes and not other times—but I discovered too late that there’s too much variation among questions to do a within-subjects analysis given the data volume we’re likely to have anytime soon. So in the analyses that follow, I’m comparing question/user pairs across various conditions.
The principle here is that we’re comparing question histories which, except for this intervention, should be roughly equivalent. There’s a lot of inter-question variance, but so long as we’re looking across several hundred histories, that variance should mostly wash out across the conditions.
Retry intervention causes 5-10pp accuracy lift in first two repetitions
Accuracy differences for questions forgotten on prior attempt, with vs. without retry…
- First repetition: 41% vs 32%
- Second repetition, also forgotten with retry in-essay: 54% vs 44%
- Second repetition, also forgotten without retry in-essay: 46% vs 36%
- Second repetition, remembered in-essay: 67% vs 61%
Note that this data suggests that the impact of retries roughly “stack” in these initial reviews. A question forgotten twice, with retries both times, is remembered 54% of the time upon its second repetition. But a question forgotten twice without any retries is remembered 36% of the time, an 18pp difference.
The practical impact here is that without retry, users are somewhat substantially more likely to repeatedly lapse. And the expected number of repetitions required to maintain a question for the first year will be somewhat higher.
Retry intervention has less effect after multiple successes
Third repetition accuracy differences for questions remembered in-essay and at the first repetition, then forgotten (with vs. without retry): 79% vs. 78%
Third repetition accuracy differences for questions forgotten in-essay (with vs. without retry) then remembered in first and second repetitions: 91% vs. 88%
Retry may have a bigger impact than forgetting
This per-card plot (20220117114202) compares per-card recall between 2021 users (who have a 1 week initial interval) and 2019 users (with a 1 day initial interval):
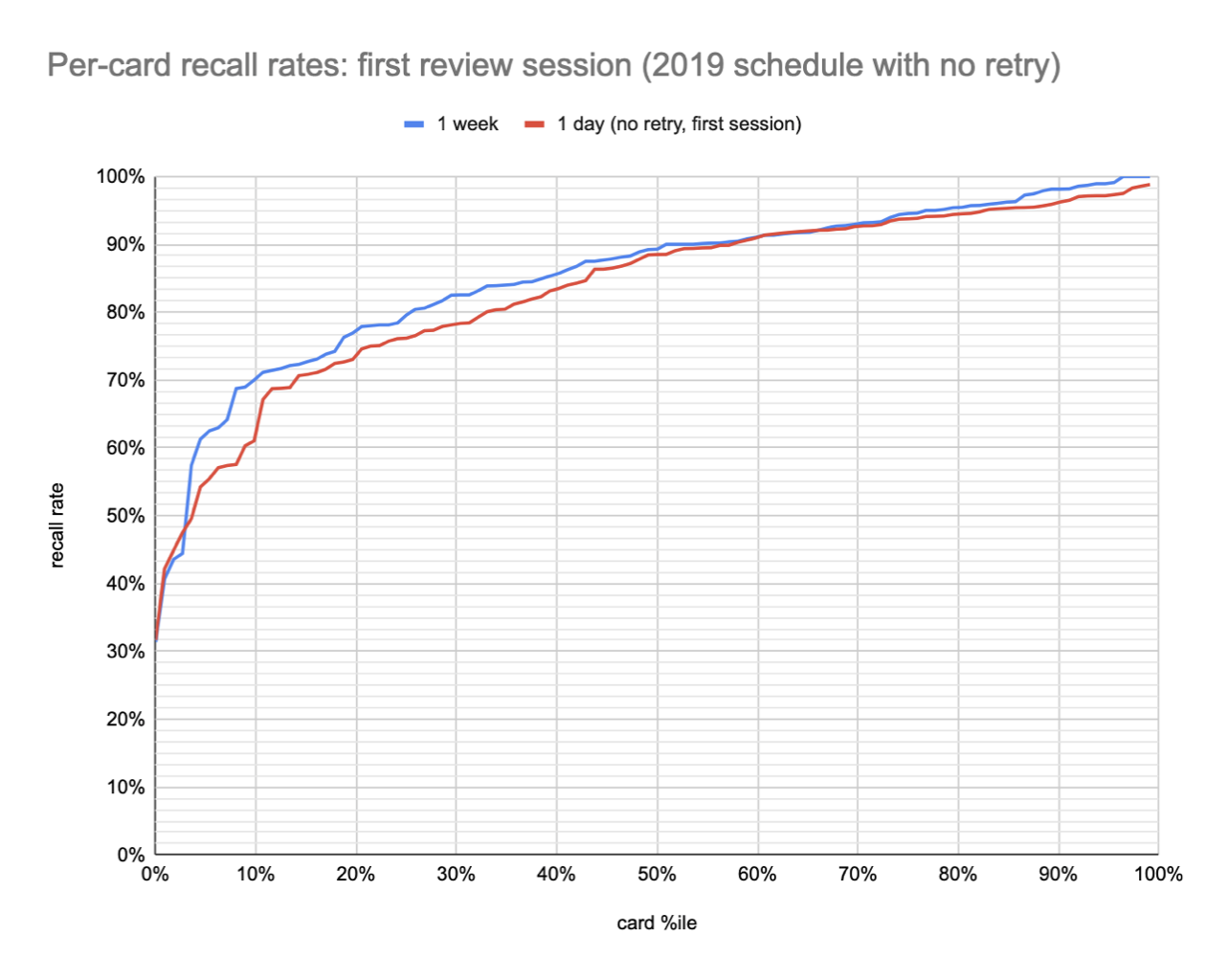
Note that the “1 day” users generally perform worse, even though their review is much sooner!
We can also compare original and aggressiveStart users in a scenario of early forgetting:
Refining, for aggressiveStart:
- forgotten in-essay
- remembered in first session (5 days later)
- forgotten in second session (2 weeks later)
- … third session? (5 days later)
20211118111432: 74% (510 readers, 949 reviews)
For original (which had no retry):
- forgotten in-essay
- remembered in first session (1 day later)
- forgotten in second session (1 day later)
- … third session? (1 day later)
20211118111922: 71% (420 readers, 671 reviews)
I noticed this when trying to understand the impact of scheduling too late (see Log: Quantum Country analysis, 2021-11-18). The original users have a much more conservative schedule, which should be helping, but they do slightly worse than the aggressiveStart readers who have their second sessions scheduled “much too late” by comparison. The best explanation I can give of this is that the aggressiveStart readers have retry.
Discussion
My intuition here is that the retry intervention mostly matters in what I think of as the “learning phase”: i.e. you’re still really internalizing the information for the first time, rather than preventing forgetting of something you once knew well.
In essence, the mechanism creates an opportunity for extra Retrieval practice when you’re relatively likely to successfully recall the answer (i.e. because you were just shown the correct answer a few minutes earlier). The Spacing effect suggests that it might be even better to retry later—perhaps half a day or a day. But waiting until the next review session is too long for effective Retrieval practice, since you’ve probably forgotten the correct answer by then, and since (it seems) retrieval practice is less effective when the correct answer is not recalled.
For methods, see qcc/scripts/analyzeReviewFlowRetry.ts with data drawn from 20210203102105
Older, less controlled analysis: (Superseded) Lapsed question accuracy remains iffy, despite retry and interval-shortening