Andyʼs working notes
About these notesExtremely data-dense texts need a different mnemonic medium design
Looking at Cell Biology by the Numbers, it’s difficult to imagine extending any of the designs for the Mnemonic medium I’ve yet imagined to it. The data is just too dense. There’s too much variability in the numbers one might choose to remember. For example, consider this table: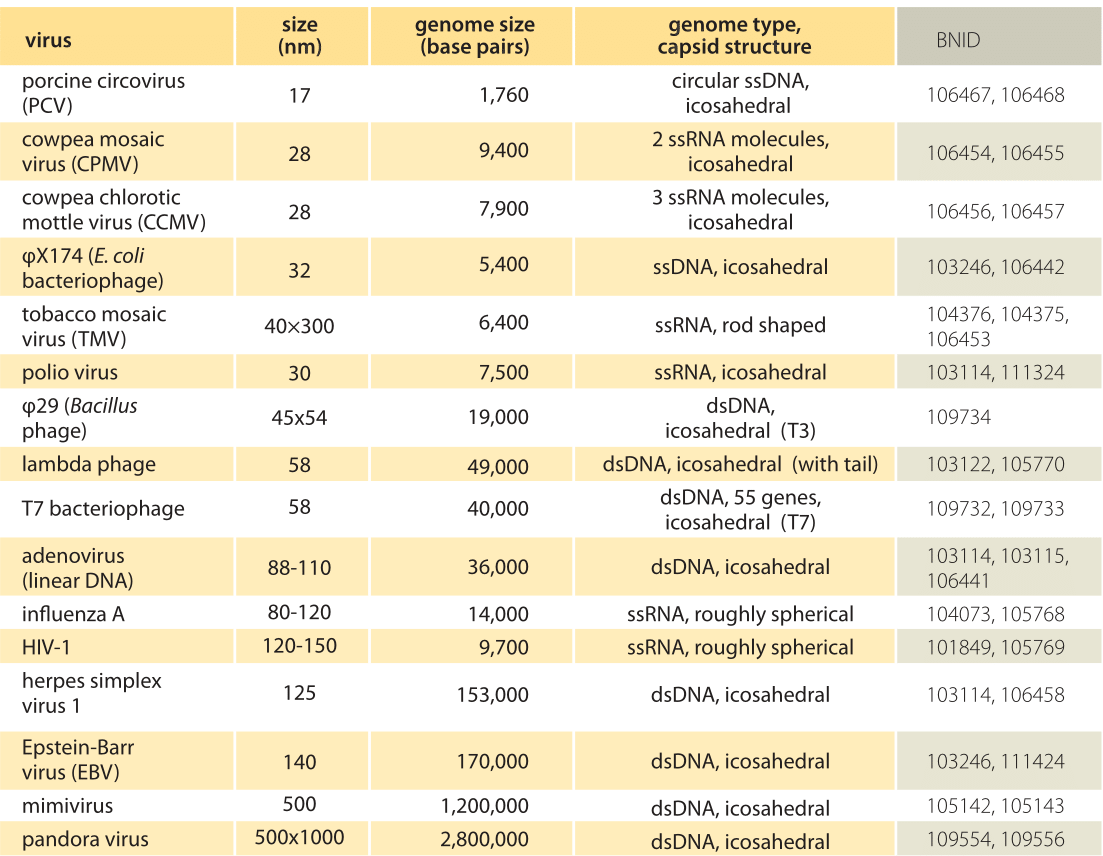
16 names associated with 2 numbers each! I’d probably approach this with a summary prompt:
Q. What’s the rough range of virus sizes?
A. A few tens to a few hundreds of nanometers.
Q. What’s the rough range of number of base pairs in a virus?
A. $10^3$ - $10^6$
Along with a few more specific prompts to anchor my memory; for example:
Q. How big is a polio virus?
A. 30 nm
Q. How many base pairs in a polio virus?
A. 7,500
But other readers might be interested in remembering a specific subset of concrete numbers. They might want more or less granularity of accuracy. This seems really tough to handle! It might make sense for readers to point to the specific cells in that table they’d like. But it’s hard to imagine an author going through and writing all those prompts! Machine generation could work from a template, I guess. But having all those prompts in the sidebar would be a nightmare. The image is 500pt high, and my minimum prompt size is 80pt. So I can only fit ~6 prompts alongside this table in a natural layout. Yikes.
Maybe the right answer here is for the author to be much more opinionated about what people should take away. This flies in the face of a lot of the ideas described in The mnemonic medium should give readers control over the prompts they collect, but as a reader, I feel really overwhelmed by this textbook. I want more guidance about what I should take away!