Andyʼs working notes
About these notes(archived) Log: exploring the impact of retry mechanics on Quantum Country
2021-02-08
Merged into Log: Quantum Country analysis
2021-02-01
Implemented a script to analyze longer paths, looking for stationarity and convergence patterns. It’s in qcc/scripts/analyzeReviewFlow.ts. 20210203102105
2021-01-28
A thought from this morning: we’ve seen that P(R, X) = P(X, R). Will P(√, X, R) = P(√, R, X)? I’m pretty sure I do have enough samples to look at that. It’s interesting to see that already, P(√, X) is quite close to P(√, R)—within error bounds. Once you’ve got a √ under your belt, at all, the impact of retry seems to diminish substantially.
I will soon-ish have enough samples to look at P(R, √, ) and P(X, √, *). It’s fascinating the way that these paths have converged. I’m very curious to see if they’ll *stay converged. With a few hundred samples, my error bars are several pp wide, so it’ll be hard to tell.
2021-01-26
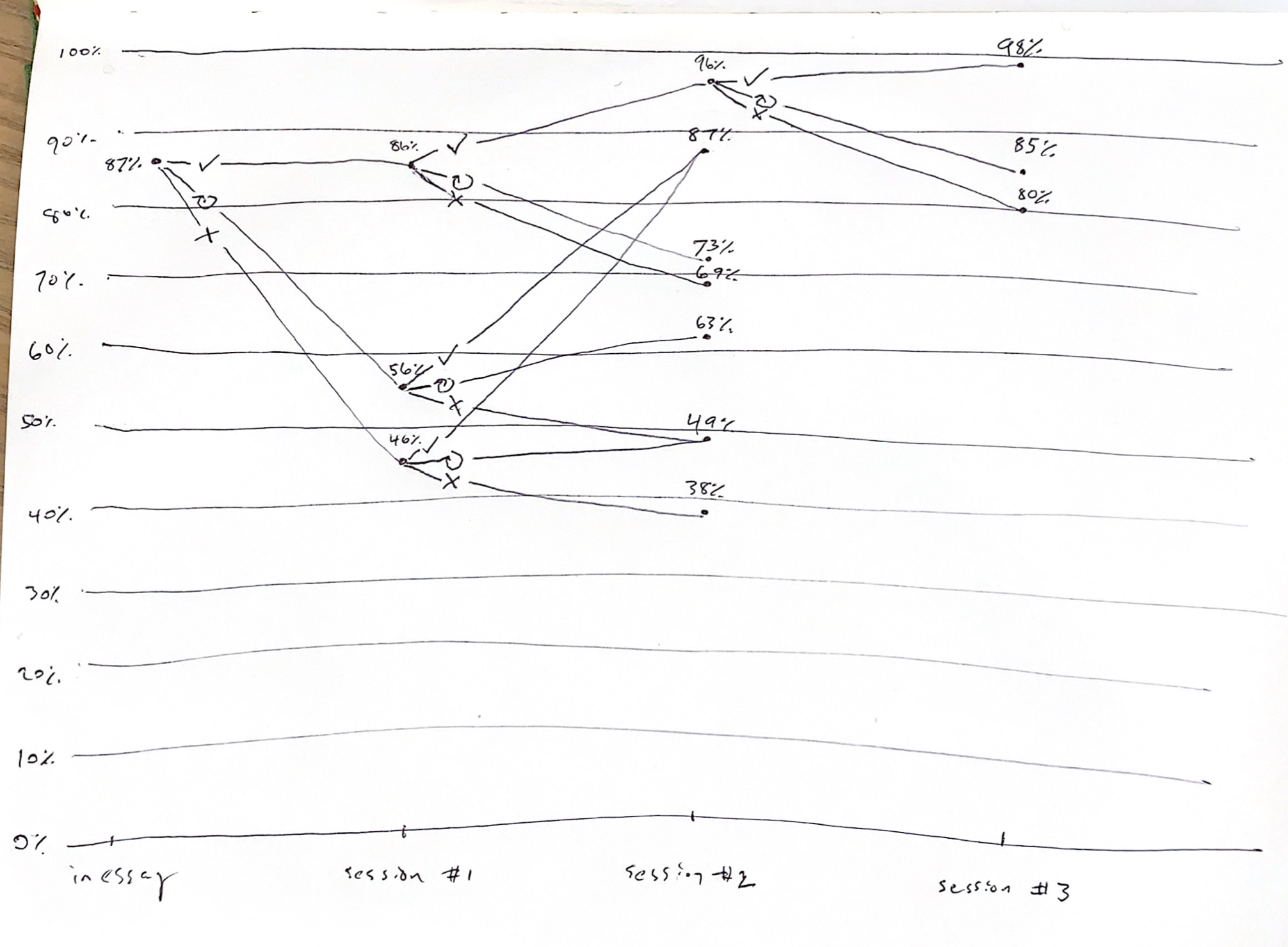
I want to look at P(C3 | C0, C1). The other branches won’t have enough samples yet, I expect. (20210126090736). Accuracies continue to rise with the same pattern: 98%, 85%, and 80% for correct, retry, and forgot respectively (N=2377, 164, 81, so not many samples for two of the branches).
It’s interesting that the lapse recovery rates are so high at this point. Makes me wonder whether the key issue for people forgetting in their second session was the interval length. 96% remembered; the 4% who didn’t had remembered two weeks prior, after a five day interval. Maybe two weeks was just too long an interval. 80%+ were able to remember again five days later.
The fact that 98% remember correctly 1 month later in review session 3 is pretty amazing. It suggests we could be much more aggressive! That’s certainly a theme here. From this point are they basically golden? Presumably from here success/failure basically just comes down to successful tuning of the interval.
Reran numbers for P(C1) because I’d misread them (20210126102352): 86%, 56%, 46% for √, withRetry, skipRetry.
(page 72)
2021-01-25
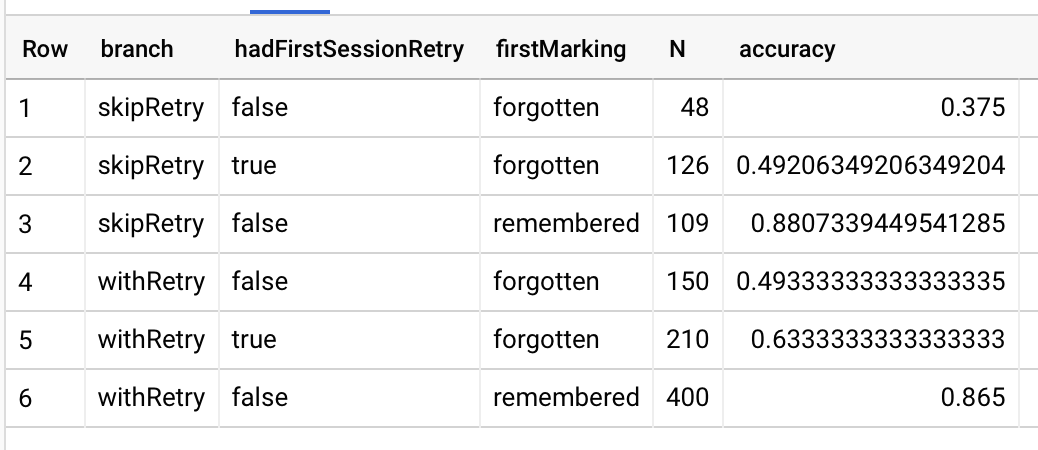
I realized over the weekend: is it possible that the big differences between P(C1 | withRetry) and P(C1 | skipRetry) which I found on 01/21 are actually just due to different distributions of readers getting a chance to retry in that first session? As I type that out, I realize that those odds should be evenly distributed among the two groups. Even so, I’ll go ahead and control for it (20210125090638).
OK, no, the difference is not due to a difference in the distribution of first session retries. In fact, splitting by first session retry lets me see the magnitude of the effect again.
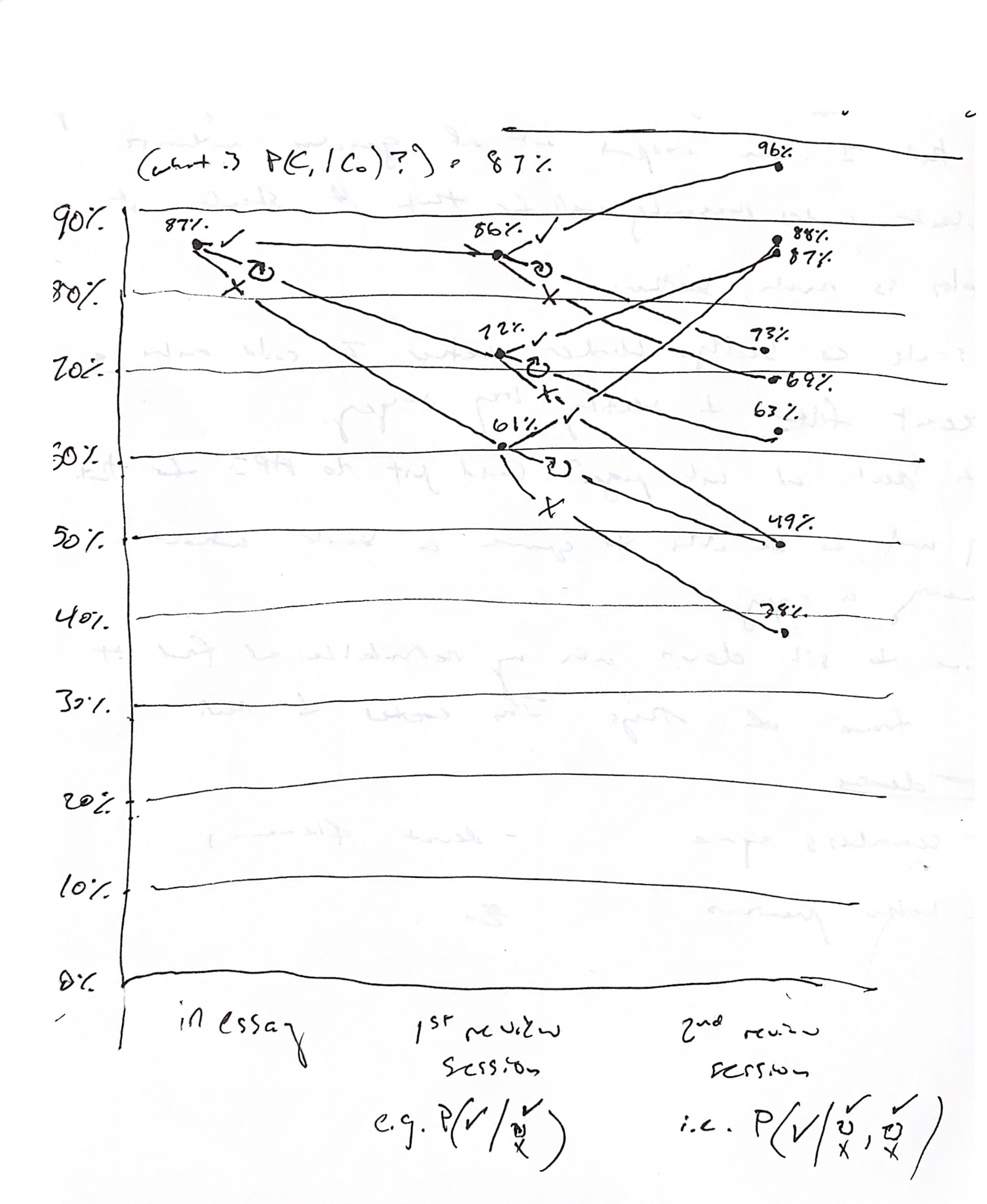
Found myself wondering: what’s P(C1 | C0) for this cohort? 87%. (20210125091956). If I limit the sample to users who make it to review session #2, it’s 86% (N=15477, users = 277). (20210125093223)
And what’s P(C0) for the same cohort? 87% (N=17026, users=242).
What’s P(C2 | C0)? 96%, 73%, 69% for √, retry, X respectively. (20210125095112)
Wow, OK. So among people who forgot the answer in-essay and in the first review session:
- those who got to retry both times did best: 63% in the second session
- those who didn’t get to retry either time did worst: 38% in the second session
- the other two branches—those who got to retry only one time—both got 49% in the second session!
- very interesting that there’s this apparent path-independence to the impact of retry
And for those who forgot the answer in-essay but remembered it in the first review session, it didn’t really matter whether or not they got to retry in-essay! Both paths did equally well in the second review session.
Where to next? Not sure yet! There are really two interesting things going on here: the dynamics of missed/not-missed questions, and the dynamics of retries. The hypothesis that’s emerging is: retries matter less the more stable your memory is. I suppose I should look at 3rd review session data next! The queries get more baroque from here.
It’s quite interesting to note that if you get a prompt right in-essay, then right in the first review session, you have a 96% chance of getting it right two weeks later. Amazing. Means we could be much more aggressive with scheduling, really. How long does that persist?
2021-01-21
I’ve been noodling on the question of how to interpret the apparent durable decline in performance readers experienced when they weren’t able to retry questions they missed within the essay.
I realized that I haven’t yet distinguished between two interpretations:
- The conditional accuracy distributions in the second review session are the same between the two cohorts, but the skipRetry population consists of a larger proportion of people with missed answers in the first session
- The probability that a reader remembers an answer in the second session is lower for skipRetry readers than for withRetry readers, even if they were able to remember the answer in the first session.
Those are numerical interpretations that I don’t quite know how to map to reality, but let’s start by getting the conditional probabilities (20210121092659)
- skipRetry:
- P(C2 | C1) = 0.88 (N=101)
- P(C2 | ~C1) = 0.45 (N=162)
- withRetry:
- P(C2 | C1) = 0.87 (N=381)
- P(C2 | ~C1) = 0.57 (N=359)
Very interesting! The reality seems to be a third interpretation: the durable effect applies only to P(C2 | N1, skipRetry)! Intuitively, that sort of makes sense: P(C2 | C1, skipRetry) folks have “got it” to a greater degree, so what happened within the essay matters less.
It’s also true that P(C1 | withRetry) > P(C1 | skipRetry), which magnifies the effect in the downstream joint distribution.
What’s actually happening, though? What do these observations actually mean? At a high level: correctly retrieving the answer does matter for downstream retention. There’s some accumulation, too, but only when the user’s memory is still poor in the first review session: two retry bouts has a greater impact than one retry bout, but one retry followed by one correct answer is roughly the same as no retries followed by a correct answer.
Or… maybe these numbers are just artifacts. The 95% CIs are 5 and 7%, so they overlap. The values are so close to 50% that the intervals are enormous, even with hundreds of samples. Even 1000 samples would only bring the 95% CIs down to 3%. I’d need 5000 samples to get down to 1%. That’ll take all year.
It’s worth noting that the P(C2 | C1) cases are recalling after two weeks, whereas the P(C2 | ~C1) cases are attempting recall after 5 days. Big difference! Big picture, if they can retain the answer for 5 days, they’re very likely to be able to then retain it for two weeks, irrespective of what happened in the first essay. But if they failed to retain the answer for 5 days, presence/absence of retry in the essay has a measurable impact on their retention after 5 more days.
Where to go from here? I’m not sure yet. Big picture theory seems to be that retry matters more when your memory is less stable, but error bars are wide enough that in-essay and first session impact could in fact be the same.
2021-01-20
I’ll begin by looking at in-essay errors, including only the lapses where the subsequent review was scheduled using the standard interval.
First, let’s just do a gross comparison of the two groups.
- Get rows which have had 1 prior forgotten response in essay and no other prior reviews
- Get rows which have had >= 1 prior forgotten response and >= 1 prior retry in essay and no prior reviews outside of the essay
This time (20210120103846) I got a pretty substantial difference: 57% accuracy (N=991) vs. 49% accuracy (N=219).
Splitting by interval (20210120104330) didn’t show me much, though with more samples the two-week bucket might be interesting (it shows a 15pp decline right now). The data here suggests that scheduling a shorter interval might help (64% accuracy for 3 days vs. 59% for 5 days). It’s not a huge difference. I’m curious what 1 day would do, but in practice, our “batching” behavior makes that difficult to examine. The impact of the 3-day intervention may have been diminished by batching, too. Still, 5pp is 5pp. 64% for the 3-day-with-retry subgroup vs. 48% for the 5-day-with-no-retry subgroup is a big difference. If you could add just one more intervention that large, you’d be basically done!
These accuracy rates for lapsed questions are quite low! It’s an important thing for me to remember: if a person’s forgotten an answer, they’re quite likely to forget it again.
Note to self: it’s not at all clear to me that accuracy is the right way to look at this. Maybe the skipRetry group actually learns more durably and efficiently in the long term because they had a more difficult first review session. What about the next time these same users review these same questions (20210120105625)? Very interesting: the difference persists! The readers who were able to retry the first time around averaged 71% (N=434, 95% CI = 4%); those who weren’t averaged 50% (N=50, 95% CI = 13%). Both improved their accuracy relative to the first review session, but there’s a persistent deficit for the users who weren’t able to retry. I wonder how long it persists.
These samples sizes are pretty small because of the restriction that we didn’t manipulate the reviewers’ interval. Relaxing that restriction (20210120111430), we obtain:
- readers who were able to retry the first time around averaged 72% (N=732, 95% CI = 3%)
- those who weren’t averaged 61% (N=257, 95% CI = 6%)
That’s encouraging—there’s likely to be some regression to the mean, but the effect probably won’t go away. We don’t have enough samples to go out another session from here, but we should with another month or two of data.
What is this durability effect? One model of memory mechanisms suggests that as the learning activity gets more challenging, the memories become more stable. But that’s not what this data suggests. Intuitively, my sense is that reinforcement won’t be effective until the learner has “got it” in some sense. And many of the learners who never got to retry still don’t “have it.” I guess this is an argument for Anki’s “learn mode,” but in my experience it’s much too conservative.
OK. What about readers who remembered the answers correctly in the essay but who forgot in the course of their first review session? How did the chance to retry affect their second review session? (20210120112852)
- second session accuracy for lapses with retry in first review session: 73% (N=342, 95% CI ±6%)
- second session accuracy for lapses without retry in first review session: 67% (N=132, 95% CI ±8%)
Not enough samples to be confident, but it looks like there’s an effect here too. Simple first hypothesis: retry matters more when memory stability is low. This isn’t really interesting insofar as what it tells us about “retry” as an intervention mechanism: it’s much more interesting in terms of what it suggests about memory reinforcement in general. Though I don’t think I can quite articulate what I think it is that’s being said yet.
Query listings
20210120103846
WITH
logs AS (
SELECT
*,
COUNTIF(reviewMarking="forgotten"
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayLapses,
COUNTIF(isRetry IS TRUE
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayRetries,
RANK() OVER (PARTITION BY userID, cardID ORDER BY timestamp) AS reviewNumber,
TIMESTAMP_DIFF(LAG(nextDueTimestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), LAG(timestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), MILLISECOND) AS delta
FROM
`logs.reviews`
WHERE
cardID IN (
SELECT
cardID
FROM
`logs.latestEssaysCards`
WHERE
essayName="qcvc") ),
samples AS (
SELECT
*,
IF
(essayLapses >= 1
AND essayRetries >= 1
AND reviewNumber = essayRetries + 2
AND sessionID IS NOT NULL,
"withRetry",
IF
(essayLapses = 1
AND reviewNumber = 2
AND isRetry IS FALSE
AND sessionID IS NOT NULL,
"skipRetry",
NULL)) AS branch
FROM
logs
WHERE
(delta = beforeInterval
OR delta = 0)
AND timestamp >= TIMESTAMP("2020-10-28") )
SELECT
branch,
COUNT(*) AS N,
COUNTIF(reviewMarking="remembered")/COUNT(*) AS accuracy
FROM
samples
WHERE
branch IS NOT NULL
GROUP BY
branch
20210120104330
WITH
logs AS (
SELECT
*,
COUNTIF(reviewMarking="forgotten"
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayLapses,
COUNTIF(isRetry IS TRUE
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayRetries,
RANK() OVER (PARTITION BY userID, cardID ORDER BY timestamp) AS reviewNumber,
TIMESTAMP_DIFF(LAG(nextDueTimestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), LAG(timestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), MILLISECOND) AS delta
FROM
`logs.reviews`
WHERE
cardID IN (
SELECT
cardID
FROM
`logs.latestEssaysCards`
WHERE
essayName="qcvc") ),
samples AS (
SELECT
*,
IF
(essayLapses >= 1
AND essayRetries >= 1
AND reviewNumber = essayRetries + 2
AND sessionID IS NOT NULL,
"withRetry",
IF
(essayLapses = 1
AND reviewNumber = 2
AND isRetry IS FALSE
AND sessionID IS NOT NULL,
"skipRetry",
NULL)) AS branch
FROM
logs
WHERE
timestamp >= TIMESTAMP("2020-10-28") )
SELECT
branch,
delta,
COUNT(*) AS N,
COUNTIF(reviewMarking="remembered")/COUNT(*) AS accuracy
FROM
samples
WHERE
branch IS NOT NULL
GROUP BY
branch, delta
ORDER BY branch, delta
20210120105625
WITH
logs AS (
SELECT
*,
COUNTIF(reviewMarking="forgotten"
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayLapses,
COUNTIF(isRetry IS TRUE
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayRetries,
RANK() OVER (PARTITION BY userID, cardID ORDER BY timestamp) AS reviewNumber,
TIMESTAMP_DIFF(LAG(nextDueTimestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), LAG(timestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), MILLISECOND) AS delta
FROM
`logs.reviews`
WHERE
cardID IN (
SELECT
cardID
FROM
`logs.latestEssaysCards`
WHERE
essayName="qcvc") ),
samples AS (
SELECT
*,
IF
(essayLapses >= 1
AND essayRetries >= 1
AND reviewNumber = essayRetries + 2
AND sessionID IS NOT NULL,
"withRetry",
IF
(essayLapses = 1
AND reviewNumber = 2
AND isRetry IS FALSE
AND sessionID IS NOT NULL,
"skipRetry",
NULL)) AS branch
FROM
logs
WHERE
(delta = beforeInterval
OR delta = 0)
AND timestamp >= TIMESTAMP("2020-10-28") ),
nextReviews AS (SELECT l.userID, l.cardID, ANY_VALUE(r.branch) AS branch, MIN(l.timestamp) AS timestamp FROM `logs.reviews` AS l JOIN samples AS r ON (l.userID = r.userID AND l.cardID = r.cardID AND l.sessionID != r.sessionID AND l.timestamp > r.timestamp) GROUP BY userID, cardID),
nextSamples AS (SELECT * FROM `logs.reviews` JOIN nextReviews USING (userID, cardID, timestamp))
SELECT branch, COUNT(DISTINCT userID) AS users, COUNT(*) AS N, COUNTIF(reviewMarking="remembered")/COUNT(*) AS accuracy FROM nextSamples GROUP BY branch
20210120111430
WITH
logs AS (
SELECT
*,
COUNTIF(reviewMarking="forgotten"
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayLapses,
COUNTIF(isRetry IS TRUE
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayRetries,
RANK() OVER (PARTITION BY userID, cardID ORDER BY timestamp) AS reviewNumber,
TIMESTAMP_DIFF(LAG(nextDueTimestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), LAG(timestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), MILLISECOND) AS delta
FROM
`logs.reviews`
WHERE
cardID IN (
SELECT
cardID
FROM
`logs.latestEssaysCards`
WHERE
essayName="qcvc") ),
samples AS (
SELECT
*,
IF
(essayLapses >= 1
AND essayRetries >= 1
AND reviewNumber = essayRetries + 2
AND sessionID IS NOT NULL,
"withRetry",
IF
(essayLapses = 1
AND reviewNumber = 2
AND isRetry IS FALSE
AND sessionID IS NOT NULL,
"skipRetry",
NULL)) AS branch
FROM
logs
WHERE
timestamp >= TIMESTAMP("2020-10-28") ),
nextReviews AS (SELECT l.userID, l.cardID, ANY_VALUE(r.branch) AS branch, MIN(l.timestamp) AS timestamp FROM `logs.reviews` AS l JOIN samples AS r ON (l.userID = r.userID AND l.cardID = r.cardID AND l.sessionID != r.sessionID AND l.timestamp > r.timestamp) GROUP BY userID, cardID),
nextSamples AS (SELECT * FROM `logs.reviews` JOIN nextReviews USING (userID, cardID, timestamp))
SELECT branch, COUNT(*) AS N, COUNTIF(reviewMarking="remembered")/COUNT(*) AS accuracy FROM nextSamples GROUP BY branch
20210120112852
WITH
logs AS (
SELECT
*,
COUNTIF(reviewMarking="forgotten"
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayLapses,
COUNTIF(reviewMarking="forgotten"
AND sessionID IS NOT NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS sessionLapses,
COUNTIF(isRetry IS TRUE
AND sessionID IS NOT NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS sessionRetries,
COUNT(DISTINCT sessionID) OVER (PARTITION BY userID, cardID) AS sessionNumber,
RANK() OVER (PARTITION BY userID, cardID, sessionID ORDER BY timestamp) AS sessionReviewNumber,
TIMESTAMP_DIFF(LAG(nextDueTimestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), LAG(timestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), MILLISECOND) AS delta
FROM
`logs.reviews`
WHERE
cardID IN (
SELECT
cardID
FROM
`logs.latestEssaysCards`
WHERE
essayName="qcvc") ),
samples AS (
SELECT
*,
IF
(essayLapses = 0
AND sessionLapses >= 1
AND sessionNumber = 2
AND sessionReviewNumber = 1
AND sessionID IS NOT NULL,
IF (sessionRetries >= 1, "withRetry", "skipRetry"), NULL) AS branch
FROM
logs
WHERE
(delta = beforeInterval
OR delta = 0)
AND timestamp >= TIMESTAMP("2020-10-28") )
SELECT branch, COUNT(DISTINCT userID) AS users, COUNT(*) AS N, COUNTIF(reviewMarking="remembered")/COUNT(*) AS accuracy FROM samples WHERE branch IS NOT NULL GROUP BY branch
20210121092659
WITH
logs AS (
SELECT
*,
COUNTIF(reviewMarking="forgotten"
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayLapses,
COUNTIF(isRetry IS TRUE
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayRetries,
RANK() OVER (PARTITION BY userID, cardID ORDER BY timestamp) AS reviewNumber,
TIMESTAMP_DIFF(LAG(nextDueTimestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), LAG(timestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), MILLISECOND) AS delta
FROM
`logs.reviews`
WHERE
cardID IN (
SELECT
cardID
FROM
`logs.latestEssaysCards`
WHERE
essayName="qcvc") ),
samples AS (
SELECT
*,
IF
(essayLapses >= 1
AND essayRetries >= 1
AND reviewNumber = essayRetries + 2
AND sessionID IS NOT NULL,
"withRetry",
IF
(essayLapses = 1
AND reviewNumber = 2
AND isRetry IS FALSE
AND sessionID IS NOT NULL,
"skipRetry",
NULL)) AS branch
FROM
logs
WHERE
timestamp >= TIMESTAMP("2020-10-28") ),
nextReviews AS (SELECT l.userID, l.cardID, ANY_VALUE(r.branch) AS branch, MIN(l.timestamp) AS timestamp, ANY_VALUE(r.reviewMarking) AS firstMarking FROM `logs.reviews` AS l JOIN samples AS r ON (l.userID = r.userID AND l.cardID = r.cardID AND l.sessionID != r.sessionID AND l.timestamp > r.timestamp) GROUP BY userID, cardID),
nextSamples AS (SELECT * FROM `logs.reviews` JOIN nextReviews USING (userID, cardID, timestamp))
SELECT branch, firstMarking, COUNT(*) AS N, COUNTIF(reviewMarking="remembered")/COUNT(*) AS accuracy FROM nextSamples WHERE branch IS NOT NULL GROUP BY branch, firstMarking ORDER BY branch, firstMarking
20210125090638
WITH
logs AS (
SELECT
*,
COUNTIF(reviewMarking="forgotten"
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayLapses,
COUNTIF(isRetry IS TRUE
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayRetries,
COUNTIF(isRetry IS TRUE
AND sessionID IS NOT NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS sessionRetries,
RANK() OVER (PARTITION BY userID, cardID ORDER BY timestamp) AS reviewNumber,
TIMESTAMP_DIFF(LAG(nextDueTimestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), LAG(timestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), MILLISECOND) AS delta
FROM
`logs.reviews`
WHERE
cardID IN (
SELECT
cardID
FROM
`logs.latestEssaysCards`
WHERE
essayName="qcvc") ),
samples AS (
SELECT
*,
IF
(essayLapses >= 1
AND essayRetries >= 1
AND reviewNumber = essayRetries + 2
AND sessionID IS NOT NULL
AND isRetry IS NOT TRUE, -- i.e. they retried successfully within the essay
"withRetry",
IF
(essayLapses = 1
AND reviewNumber = 2
AND isRetry IS FALSE
AND sessionID IS NOT NULL,
"skipRetry",
NULL)) AS branch
FROM
logs
WHERE
timestamp >= TIMESTAMP("2020-10-28") ),
nextReviews AS (SELECT l.userID, l.cardID, MIN(l.timestamp) AS timestamp, ANY_VALUE(r.branch) AS branch, ANY_VALUE(r.reviewMarking) AS firstMarking FROM `logs.reviews` AS l JOIN samples AS r ON (l.userID = r.userID AND l.cardID = r.cardID AND l.sessionID != r.sessionID AND l.timestamp > r.timestamp) WHERE branch IS NOT NULL GROUP BY userID, cardID),
nextSamples AS (SELECT * FROM (SELECT * EXCEPT (branch) FROM samples) JOIN nextReviews USING (userID, cardID, timestamp))
SELECT branch, sessionRetries > 0 AS hadFirstSessionRetry, firstMarking, COUNT(*) AS N, COUNTIF(reviewMarking="remembered")/COUNT(*) AS accuracy FROM nextSamples GROUP BY branch, firstMarking, hadFirstSessionRetry ORDER BY branch, firstMarking, hadFirstSessionRetry
20210125091956
WITH
withRank AS (SELECT *, COUNTIF(reviewMarking="forgotten") OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS lapseCount, RANK () OVER (PARTITION BY cardID, userID ORDER BY timestamp) AS reviewNumber FROM `logs.reviews` WHERE cardID IN (
SELECT
cardID
FROM
`logs.latestEssaysCards`
WHERE
essayName="qcvc") ),
samples AS (SELECT * FROM withRank WHERE reviewNumber = 2 AND timestamp >= TIMESTAMP("2020-10-28") AND lapseCount = 0)
SELECT COUNTIF(reviewMarking="remembered")/COUNT(*) AS accuracy, COUNT(*) AS N FROM samples
20210125093223
WITH
withRank AS (SELECT *, COUNTIF(reviewMarking="forgotten") OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS lapseCount, COUNT(DISTINCT sessionID) OVER (PARTITION BY userID, cardID) AS sessionNumber, RANK () OVER (PARTITION BY cardID, userID ORDER BY timestamp) AS reviewNumber FROM `logs.reviews` WHERE cardID IN (
SELECT
cardID
FROM
`logs.latestEssaysCards`
WHERE
essayName="qcvc") ),
eligibleUsers AS (SELECT DISTINCT userID FROM withRank WHERE sessionNumber = 2),
samples AS (SELECT * FROM withRank WHERE reviewNumber = 2 AND timestamp >= TIMESTAMP("2020-10-28") AND lapseCount = 0 AND userID IN (SELECT userID FROM eligibleUsers))
SELECT COUNTIF(reviewMarking="remembered")/COUNT(*) AS accuracy, COUNT(*) AS N FROM samples
20210125095112
WITH
logs AS (
SELECT
*,
COUNTIF(reviewMarking="forgotten"
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayLapses,
COUNTIF(isRetry IS TRUE
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayRetries,
COUNTIF(isRetry IS TRUE
AND sessionID IS NOT NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS sessionRetries,
RANK() OVER (PARTITION BY userID, cardID ORDER BY timestamp) AS reviewNumber,
TIMESTAMP_DIFF(LAG(nextDueTimestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), LAG(timestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), MILLISECOND) AS delta
FROM
`logs.reviews`
WHERE
cardID IN (
SELECT
cardID
FROM
`logs.latestEssaysCards`
WHERE
essayName="qcvc") ),
samples AS (
SELECT
*,
IF
(essayLapses >= 1
AND essayRetries >= 1
AND reviewNumber = essayRetries + 2
AND sessionID IS NOT NULL
AND isRetry IS NOT TRUE, -- i.e. they retried successfully within the essay
"withRetry",
IF
(essayLapses = 1
AND reviewNumber = 2
AND isRetry IS FALSE
AND sessionID IS NOT NULL,
"skipRetry",
IF (essayLapses = 0 AND reviewNumber = 2 AND isRetry IS FALSE AND sessionID IS NOT NULL, "firstCorrect", NULL))) AS branch
FROM
logs
WHERE
timestamp >= TIMESTAMP("2020-10-28") ),
nextReviews AS (SELECT l.userID, l.cardID, MIN(l.timestamp) AS timestamp, ANY_VALUE(r.branch) AS branch, ANY_VALUE(r.reviewMarking) AS firstMarking FROM `logs.reviews` AS l JOIN samples AS r ON (l.userID = r.userID AND l.cardID = r.cardID AND l.sessionID != r.sessionID AND l.timestamp > r.timestamp) WHERE branch IS NOT NULL GROUP BY userID, cardID),
nextSamples AS (SELECT * FROM (SELECT * EXCEPT (branch) FROM samples) JOIN nextReviews USING (userID, cardID, timestamp))
SELECT branch, sessionRetries > 0 AS hadFirstSessionRetry, firstMarking, COUNT(*) AS N, COUNTIF(reviewMarking="remembered")/COUNT(*) AS accuracy FROM nextSamples GROUP BY branch, firstMarking, hadFirstSessionRetry ORDER BY branch, firstMarking, hadFirstSessionRetry
20210126090736
WITH
logs AS (
SELECT
*,
COUNTIF(reviewMarking="forgotten"
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayLapses,
COUNTIF(reviewMarking="forgotten"
AND sessionID IS NOT NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS sessionLapses,
COUNTIF(isRetry IS TRUE
AND sessionID IS NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS essayRetries,
COUNTIF(isRetry IS TRUE
AND sessionID IS NOT NULL) OVER (PARTITION BY userID, cardID ORDER BY timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING) AS sessionRetries,
COUNT(DISTINCT sessionID) OVER (PARTITION BY userID, cardID) AS sessionNumber,
RANK() OVER (PARTITION BY userID, cardID ORDER BY timestamp) AS reviewNumber,
TIMESTAMP_DIFF(LAG(nextDueTimestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), LAG(timestamp) OVER (PARTITION BY userID, cardID ORDER BY timestamp), MILLISECOND) AS delta
FROM
`logs.reviews`
WHERE
cardID IN (
SELECT
cardID
FROM
`logs.latestEssaysCards`
WHERE
essayName="qcvc") ),
samples AS (
SELECT
*,
IF
(essayLapses >= 1
AND essayRetries >= 1
AND reviewNumber = essayRetries + 2
AND sessionID IS NOT NULL
AND isRetry IS NOT TRUE, -- i.e. they retried successfully within the essay
"withRetry",
IF
(essayLapses = 1
AND reviewNumber = 2
AND isRetry IS FALSE
AND sessionID IS NOT NULL,
"skipRetry",
IF (essayLapses = 0 AND sessionLapses = 0 AND reviewNumber = 3 AND isRetry IS FALSE AND sessionID IS NOT NULL, "firstCorrect", NULL))) AS branch
FROM
logs
WHERE
timestamp >= TIMESTAMP("2020-10-28") ),
nextReviews AS (SELECT l.userID, l.cardID, MIN(l.timestamp) AS timestamp, ANY_VALUE(r.branch) AS branch, ANY_VALUE(r.reviewMarking) AS firstMarking FROM `logs.reviews` AS l JOIN samples AS r ON (l.userID = r.userID AND l.cardID = r.cardID AND l.sessionID != r.sessionID AND l.timestamp > r.timestamp) WHERE branch IS NOT NULL GROUP BY userID, cardID),
nextSamples AS (SELECT * FROM (SELECT * EXCEPT (branch) FROM samples) JOIN nextReviews USING (userID, cardID, timestamp))
SELECT branch, sessionRetries > 0 AS hadFirstSessionRetry, firstMarking, COUNT(*) AS N, COUNTIF(reviewMarking="remembered")/COUNT(*) AS accuracy FROM nextSamples GROUP BY branch, firstMarking, hadFirstSessionRetry ORDER BY branch, firstMarking, hadFirstSessionRetry