Andyʼs working notes
About these notesFukumoto, M. (2018). SilentVoice: Unnoticeable Voice Input by Ingressive Speech. Proceedings of the 31st Annual ACM Symposium on User Interface Software and Technology, 237–246
An approach to Silent speech interface using a modified microphone held to the lips and an “ingressive” whisper—i.e. articulation while breathing in.
The proposed “ingressive speech” method enables ==placement of a microphone very close to the front of the mouth== without suffering from pop-noise, capturing very soft speech sounds with a good S/N ratio. It realizes ==ultra-small (less than 39dB(A)) voice leakage==, allowing us to use voice input without annoying surrounding people in public and mobile situations as well as offices and homes. By measuring airflow direction, SilentVoice can easily be separated from normal utterances with 98.8% accuracy; no activation words are needed. It can be used for voice-activated systems with a specially trained voice recognizer; ==evaluation results yield word error rates (WERs) of 1.8% (speaker-dependent condition), and 7.0% (speaker-independent condition) with a limited dictionary of 85 command sentences==. A whisper-like natural voice can also be used for real-time voice communication.
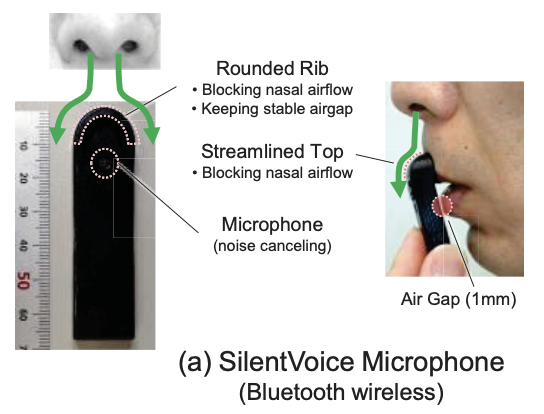
Implemented using simple hardware: a small noise-canceling microphone (Knowles WP-23501-000) is mounted in a (3d-printed?) 18x63mm “shielding plate” (which reduces leaked sound and blocks nasal airflow) with a pop-filter sheet. And straightforward software: the Bing Speech API (custom model). It’s something I’m pretty sure I could reproduce, with effort.
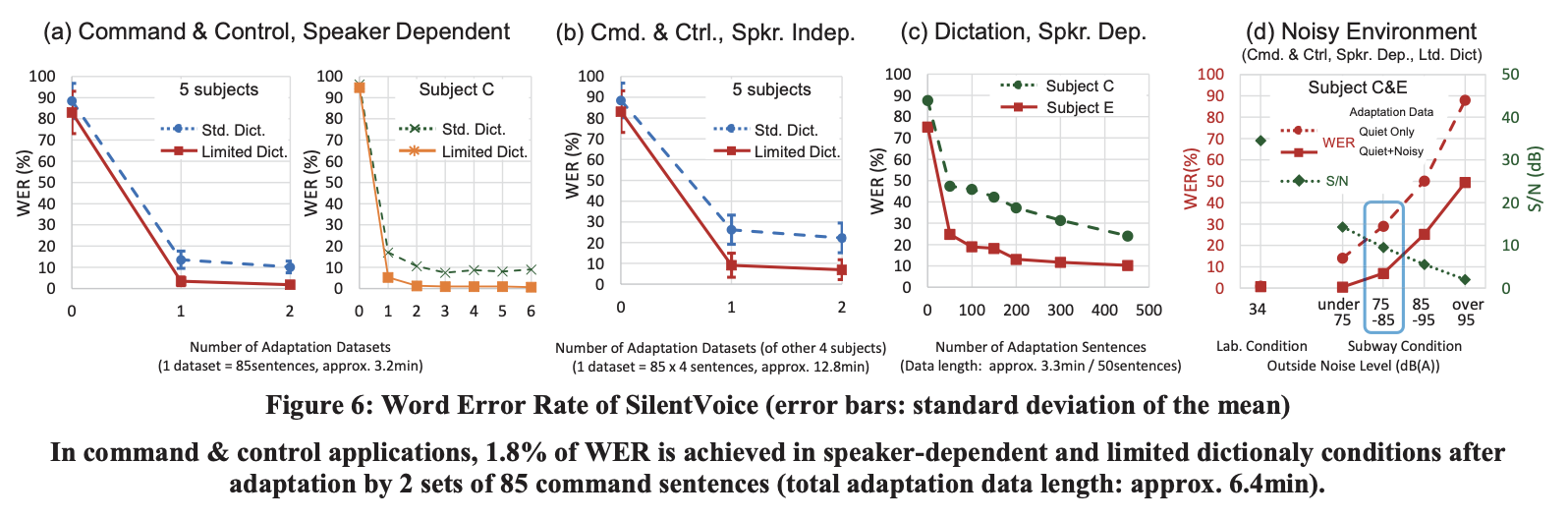
The system requires speaker-specific adaptation for good dictation performance:
For comparison, here are error rates of popular consumer transcription models (n.b. on a different data set, so not directly comparable):
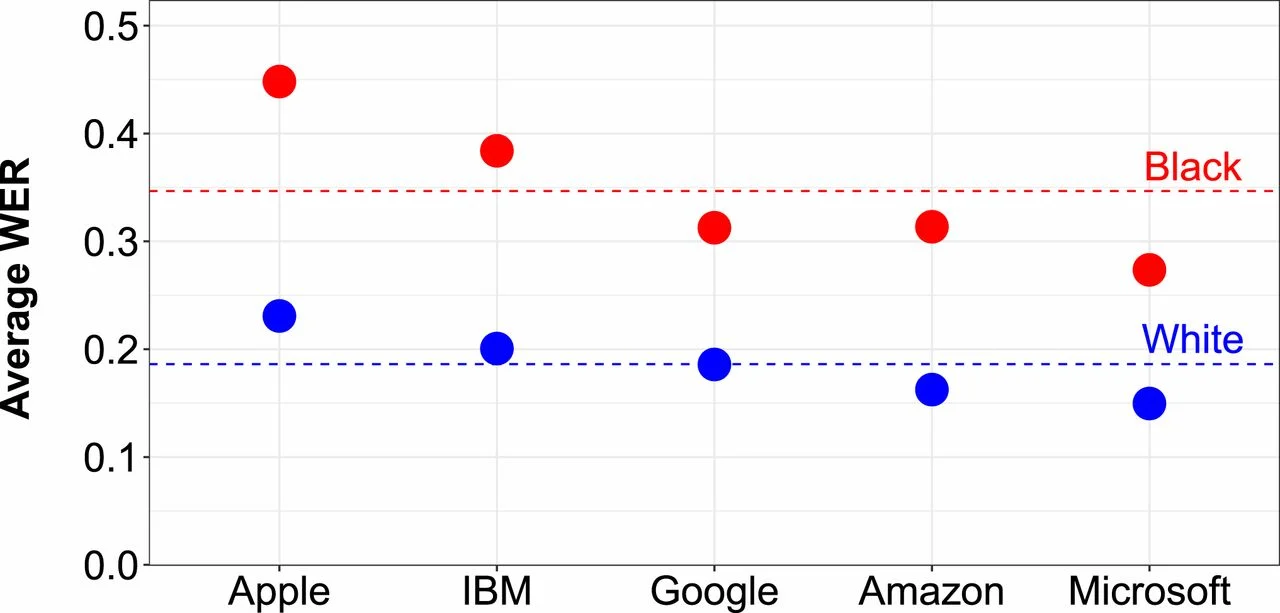
… from Koenecke, A., Nam, A., Lake, E., Nudell, J., Quartey, M., Mengesha, Z., Toups, C., Rickford, J. R., Jurafsky, D., & Goel, S. (2020). Racial disparities in automated speech recognition. Proceedings of the National Academy of Sciences, 117(14), 7684–7689. https://doi.org/10.1073/pnas.1915768117