Andyʼs working notes
About these notes2023-08-01 Patreon letter - Initial experiments in self-explanation support
Private copy; not to be shared publicly; part of Patron letters on memory system experiments
In 2019, I argued that “books don’t work” because people seem to forget a surprising fraction of what they read. No wonder it’s so hard to learn complex topics. But in the past few months, I’ve come to believe that what seems like “forgetting” in these cases is often “never having really understood in the first place.” And that when people find themselves unable to draw on what they’ve learned, they often can’t distinguish between having forgotten and never having understood, in that moment. If that’s true, and if I want to help people learn complex topics much more effectively, then I’ll need to move upstream of forgetting. That doesn’t mean ignoring memory—understanding depends heavily on memory, as we’ll discuss—but it does mean thinking about memory in a larger context.
So: what is “understanding”? How does it happen, mechanistically, when interacting with (say) a text? If someone has failed to understand something, what hasn’t happened, exactly? What factors affect those processes? What does any of that imply about possible interventions? In this letter, I’ll sketch what I’ve learned so far about these questions.
How do we understand text explanations?
What is “understanding”? Learning scientists start from high-level behavior in the world: “To understand is to be able to wisely and effectively use—transfer—what we know, in context; to apply knowledge and skill effectively, in realistic tasks and settings.”[1] They work downwards from there, asking what sort of learning activities tend to produce that high-level capacity. Meanwhile, cognitive psychologists start from the low-level mechanisms of the brain—perception, attention, processing, memory—and try to work upwards toward more complex phenomena. For them, “understanding” isn’t one thing, but an imprecise name we give to many processes working together.
The problem for designers like myself is that the two disciplines haven’t yet extended their findings far enough to meet in the middle. A principled understanding of “understanding” would help us invent new ways to bring it about. Absent that, we’ll follow the stalactites and stalagmites as far as we can go on each side; and then we’ll need imagination, intuition, and guesswork to bridge the gap.
As a first step, let me constrain the kind of understanding we’re talking about. Let’s focus on understanding an explanation from a text. Say you’re reading an explanation of the human circulatory system. Eventually, you might aim to “understand the circulatory system”. But for the moment let’s merely aim to “understand this explanation of the circulatory system.” That’s a lower bar, but it seems to be the bottleneck in many cases.
Concretely, you should be able to say what the author’s sentences mean; you should be able to explain the properties and relationships described and implied in the text; you should be able to make simple inferences relying on those details and any relevant prior knowledge. We won’t worry about automaticity or long-term retention for now. Let’s imagine that you’ve just read the explanation, and it’s fine if your answers are slow.
Cognitive psychologists call this kind of understanding “text comprehension.” Walter Kintsch’s well-studied construction–integration model divides this process into two parts[2]. First, you need to construct some kind of internal representation of the literal text on the page: read the words, parse the syntax, resolve noun references and ambiguous verb senses, etc. Kintsch calls this mental representation a textbase. If we ignore forgetting for a moment, a complete textbase will let you answer questions which only require manipulating the literal words of the author’s explanation. If you have a textbase for “Bargleborp, if left unchecked, causes hixitak”, then you can answer “Nobody noticed Bob’s bargleborp until it was too late. What happened?” (“Hixitak.”) You know what the words say but little about what they mean.
Then, you need to make meaning through integration, forming connections that aren’t on the page. You’ll link the terms and propositions in the text to things you already know, and you’ll infer details the author means but hasn’t explicitly written. Kintsch calls this integrated mental representation a situation model.
For example, in an explanation of the circulatory system, suppose you read this passage: “When a baby has a septal defect, the blood cannot get rid of enough carbon dioxide through the lungs. Therefore, it looks purple.”[3] Your textbase representation of these sentences isn’t enough to understand this explanation. Why does the blood look purple? To explain, you need to give these details meaning by connecting them to your prior knowledge about blood flow, as in this figure:
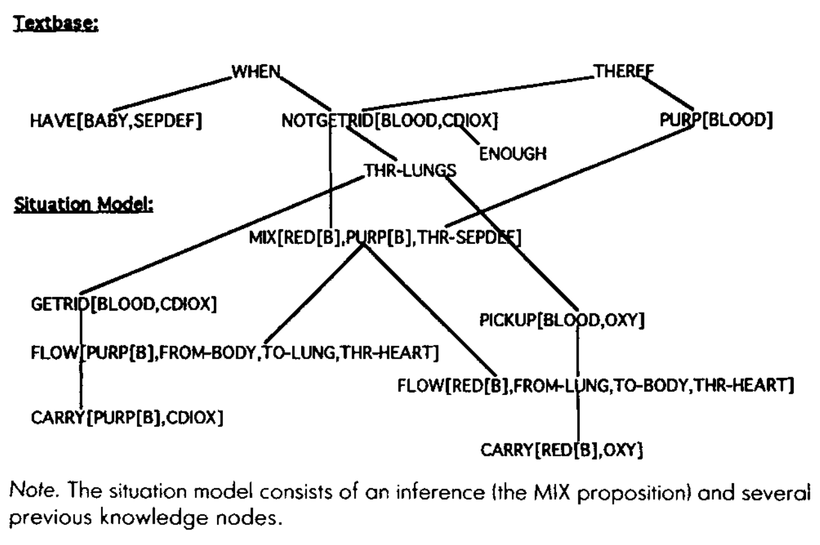
We can use this model to give a little more mechanistic color to commonplace intuitions about text comprehension and learning:
Better integration produces better memory. Propositions in both the textbase and the situation model will be encoded into long-term memory. But recall and memory consolidation are associative. If you can only “reach” a text’s elements through a single link from your prior knowledge, it will be difficult to retrieve, and it won’t get much reinforcement in later cognition. Kintsch’s experiments suggest that durable learning mostly happens by hooking new elements from a text to old elements in your knowledge base, to form a richer situation model. The more hooks, the better. You can get more hooks by processing the text more deeply or by having more prior knowledge. This accords with the intuition that it’s easier to remember new details about domains where you have a great deal of expertise.
Better memory produces better integration. As we saw in the example above, connections and inferences between nodes in the textbase often require following paths “through” nodes representing prior knowledge. This suggests a mechanistic role for memory reinforcement: you can’t traverse nodes you’ve forgotten. If chapter 2 depends on unfamiliar material from chapter 1, we need to ensure that you don’t forget details from chapter 1 before you use them to integrate explanations in chapter 2.
“Put it in your own words.” That’s common advice for students. But I’m tickled to notice that Kintsch’s model suggests you basically can’t learn without putting a text in your own words (though perhaps unconsciously). To form a well-integrated situation model, you need to connect the concepts referenced by the author’s words to the concepts which make up your prior knowledge. That is, you’re manipulating concepts here, not words. If one author talks about “getting rid of carbon dioxide through the lungs” and another about “exhaling carbon dioxide”, you’ll generally need to interpret those phrases as referring to the same conceptual nodes. If you don’t, you’ll fail to form connections across the situation models formed by the two texts.
Attention moderates comprehension. One trivial failure mode is all too familiar: sometimes your eye skips across a sentence so quickly that you never even decode the words in it. Or you read the words in a sentence, but your attention is so shallow that you never parse its thorny syntax. In these cases, you never form a textbase of the text. You might process the “surface features” of the text—for instance, noting that a particular key word was present in that part of the text—but you won’t be able to use any of that information, even on a verbatim basis. Text selection affects behavior here: in one of Kintsch’s experiments, when a text was too verbose or familiar, subjects tended to lean on their existing situation models and formed a lossy textbase representation.
Integration moderates transfer. If you find that you can only parrot what the author says verbatim, but that you struggle to put the ideas into your own words or put them to use, that’s a sign that your situation model is dominated by your textbase. That is, your mental representation consists mostly of nodes corresponding to the authors’ words and phrases. So when cues come in which aren’t shaped exactly like the text, you can’t connect them to what you’ve learned. You’ll have to work more with the text, connecting it to what you know, asking questions, and making inferences.
Self-explanation helps understanding
Kintsch’s experiments mostly ignore issues of attention, self-regulation, and reflection. His studies typically assume an ideal case—the learner constructs the best possible model they can from the text, given their prior knowledge—and asks about properties of those models. In practice, though, my sense is that comprehension issues often arise because readers haven’t constructed the best possible model given their prior knowledge. Often that’s appropriate: careful reading takes time and effort, and most books don’t deserve an unlimited budget. The ideal reader would construct exactly as good an understanding as they intend. My job in “augmentation”, then, would be about expanding the Pareto frontier. In reality, as we discussed in last month’s essay, readers often don’t understand the text as well as they intend. They fail to notice large holes in their understanding—not just of the concept, but of the explanation of the concept.
What might we do about this? We’d like to help readers do things like draw connections, monitor their comprehension, and correct holes or misapprehensions. The best-studied intervention along these lines relies on self-explanation. Michelene Chi and colleagues asked one group of students to explain a text aloud as they read; a control group re-read the passage to hold total study time constant. The explaining group performed much better on post-tests, particularly on more difficult transfer questions which required new inferences.
Within the explaining group, some students naturally produced more voluble explanations than others. Interestingly, the “high explainers” learned much more, even after controlling for differences in initial domain knowledge and verbal ability. In an open-book test, the “high explainers” almost never referred to the text, while “low explainers” (and the control group) did routinely, suggesting that the “high explainers” had internalized more of the material. Interestingly, the nature of the self-explanations also differed between these groups. The “high explainers”’ explanations were much more likely to draw connections across topics in the text, rather than just within topics. And they made more inferences in their explanations, which may explain why on the post-test, they were much more able to explain details which were only implied in the text, rather than explicitly stated.
Chi and colleagues suggest that since the “low” and “high” explainers had the same pre-test scores, their differences may be due to skills and habits of self-explanation. For example, maybe the “high explainers” have previously picked up a general strategy of making connections across topics, and a general belief that more explanation is better. This view has led to a long line of research about explicitly teaching effective self-explanation strategies.
Teaching people these sorts of strategies will probably make them more likely to understand conceptual explanations. Speaking for myself, I became a much more effective learner as I expanded my repertoire of reading techniques. But I don’t think this is enough. I read these papers on self-explanation almost a decade ago. But I don’t reliably do it—sometimes because it feels like annoying drudgery, and sometimes because it simply hasn’t occurred to me. It’s all too easy to slide into “just reading”, assuring myself that I’ve understood just fine. Often, I haven’t!
A few prototypes
One way I think about this is: the medium of prose explanation doesn’t really encourage what I want here. The default action is to continue reading. The text won’t do much to help me monitor my understanding or draw appropriate inferences; I need to watch myself continuously and notice when I become confused. If I spend more time understanding something thoroughly, the text won’t react or surface that. Compare to a conversation. In a conversation, my partner will watch for apparent confusion. They’ll ask and answer questions about the explanation. They’ll encourage me when I make the effort to understand.

In the past year’s prototypes, I’ve demonstrated various combined mediums of text-plus-linked-memory-systems, and I realize now that those come much closer to encouraging the kind of behavior I want. I’ve been doing a lot of reading with a simple system where I can highlight any text and write associated memory prompts. The prompts float alongside the associated text, and the text, in turn, is shaded to indicate the presence of the prompt. The spatial markers give me an instant visceral indication of where I’ve given the text lots of attention, and where I’ve not. And there’s a funny thing that happens: the shading is somehow viscerally rewarding! It feels good to “fill up” the sidebar, to “color in” all the “good bits”. Obviously, this can be misleading; highlighting a text feels virtuous, but you don’t want to highlight the whole page. Still, I want to stress the contrast with traditional text: this is a medium which naturally helps me notice where I’ve “gone deep” in a certain sort of way, and encourages me to do more of it. The “default path” is deeper with this medium than when I read a normal book.
Memory prompts are much more difficult to write than self-explanations. Some of that additional difficulty probably translates into richer understanding, but I suspect that a lot of it is “waste heat” lost to the idiosyncratic requirements of rewriting an explanation as a task which will produce exactly the desired kind of retrieval. So, inspired by those observations about the text-plus-linked-memory-system medium, I prototyped a reading experience which “passively rewards” self-explanation in an analogous way. As I read, I can highlight important passages and explain the passage in my own words, adding connections and color as appropriate. I can explain aloud using dictation, if I wish. Those passages are shaded to give me a clear sense of which parts I’ve explained. And, as an added measure, I send the explanation to GPT-4 and display feedback if I’ve made an error or ignored something important.
Here’s a brief video of me writing a “successful” and a “mistaken” self-explanation in a linear algebra textbook:
After a few iterations on this theme, the resulting prototypes are interesting, but not something I’ll develop further in quite this form. On the positive side, when I read with this tool, I feel confident that I understand the material quite well. But it’s also pretty unpleasant. Much of the time, typing out (or speaking) full explanations of the author’s points feels like unimportant busywork, irrespective of whether it’s helping me understand. Interestingly, I don’t always feel that way: when I find myself confused by something the author said, the exercise feels naturally rewarding.
Writing memory prompts might be much more difficult, but it also feels more valuable as an activity than written/spoken self-explanation. I think that’s because the memory prompts aren’t just chaff to be discarded when the reading experience is over. I’m not writing them for the benefit of writing them. I’m writing them so that they’ll be added to my memory practice. I’ll carry them with me after I finish reading, confident that I’ll remember all those details indefinitely.
So, I tried reframing the self-explanation activity as note-writing. What if all the self-explanations I write while reading get bundled up into a Markdown file in my note system? Then I wouldn’t be writing them just for the benefit of writing them; I’d carry them with me afterwards in my notes. Unfortunately, the results in my experiments just weren’t very compelling. I end up with a note file that’s a fragmentary and verbose summary of the original text, in my own words. But it’s not really the summary I would have written if I were trying to produce useful notes on the text. It’s not an output which really motivates its own creation.
Still, I think the two heuristics I’ve discussed are compelling. First, you want the reading medium to naturally “suggest” expert strategies. And second, those “extra” reading activities would ideally result in something you find viscerally valuable, rather than just feeling like virtuous busywork.
This relates to one way I think about my ecological niche in this space: I care, a lot, about how the reading experience feels. The educational psychology literature is littered with interventions and reading augmentation systems, but they’re more or less universally appalling experiences for readers, and the researchers seem utterly uninterested in that fact. My hope is that if I dig into the principles behind some of these systems, I can reconstitute them into something empowering and delightful.
[1] Grant Wiggins and Jay McTighe, Understanding by Design (2005), page 7.
[2] See Kintsch’s monograph, Comprehension: A Paradigm for Cognition (1998). I’m over-simplifying here: construction isn’t just about the textbase and integration about the situation model; integration is needed to form a coherent textbase, too (e.g. to resolve ambiguous interpretations); but this is a workable approximation for our purposes.
[3] This example from Kintsch, W. (1994). Text comprehension, memory, and learning. American Psychologist, 49(4), 294–303. Unfortunately, I think it actually contains a misconception about blood flow: as I understand it, blood flowing to the lungs is dark red, not purple, and that’s because it is low on oxygen, rather than because it contains carbon dioxide. But it’s a nice figure, so we’ll use it for the sake of discussion.