Andyʼs working notes
About these notesFeature net
Originally proposed by Selfridge (1959) (as the “pandemonium model”), feature nets are a theory of recognition and image constancy in Human perception.
Feature nets propose that recognition depends on a network of “detectors,” organized in layers of increasing granularity. The lowest layers would focus on simple features, like individual lines and angles; higher layers might combine those detectors to recognize letters.
Each detector has a {response threshold} which determines the {activation level} at which it will {send its signal to connected detectors in higher layers}.
Two key factors for a detector’s starting activation level: {recency} and {frequency}. Starting activation level is important because detectors with a high level {are easier to activate}.
Repetition priming (Human perception) can be framed in terms of feature nets: {activation levels will be higher after a recent presentation, so a weaker signal will trigger subsequent activations}.
But feature nets don’t fully explain top-down processing effects we observe. In particular, they can’t explain priming effects which {depend on prior knowledge}. For instance, {people told that they’re about to briefly see a word of something they can eat, or from Star Wars, are more likely to recognize the word}. Activation levels aren’t sufficient to explain this phenomenon because {it occurs even if the reference isn’t seen recently or frequently}.
Adding {bigram} detectors to our feature net makes them resistant to confusion or partial recognition: for instance, if we glimpse the word “CORN” for only 20ms, and so we only recognize the bottom curve of “O”, {the low starting activation levels of “CU” and “CQ” will lead to “CO” responding more reliably}.
N-gram detectors in feature nets help explain the word superiority effect (Human perception): {if you see only part of a letter, but are still able to recognize the full word due to well-primed higher-level detectors, you can infer the value of the missing letter from the fully-recognized word}.
Feature nets suggest that we’ll be likely to make recognition errors when {glancing at words which are similar to, but slightly different from, well-primed words}, because {perception in that case will depend mostly on starting activation levels}.
Q. How do feature nets demonstrate Distributed representation?
A. You can’t tell that e.g. a particular spelling is common just by looking at one bigram’s activation level. You have to examine the detectors in relationship to each other to see how their relative weights encode certain expectations.
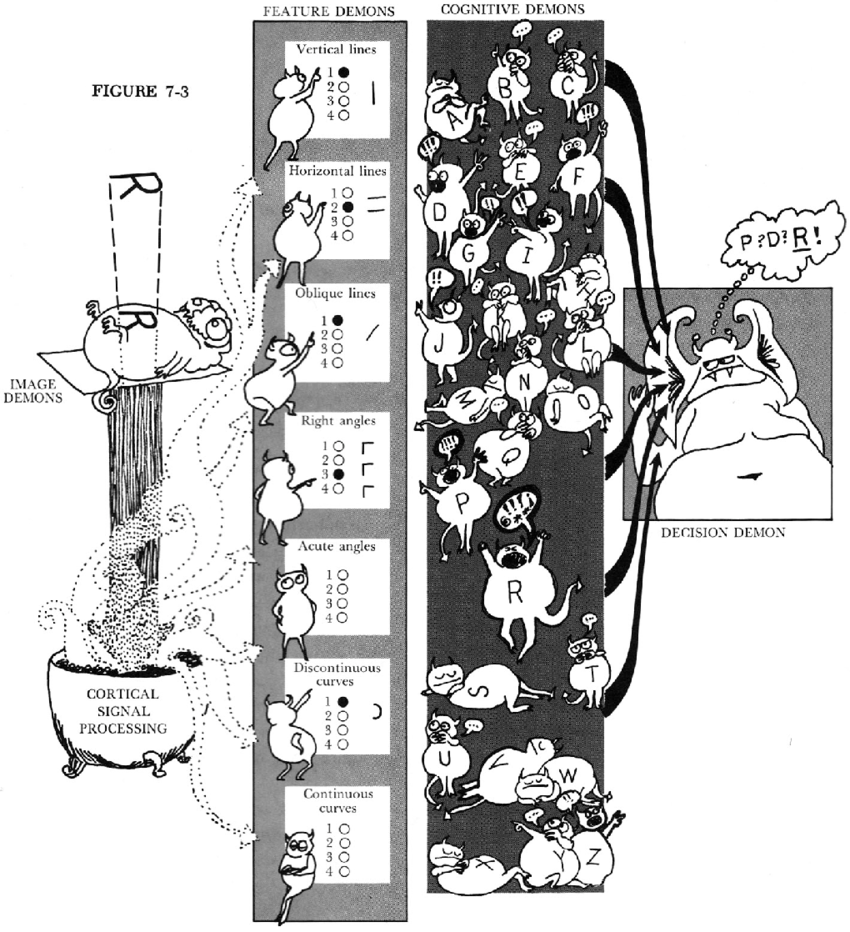
Incredible illustration from Lindsay and Norman (1972)
More elaborate feature nets (like those proposed by McClelland and Rumelhart, 1981) add inhibitory connections and intra-layer connections.
References
Lindsay, P. H., & Norman, D. A. (1972). Human information processing: An introduction to psychology. Academic Press.
Selfridge, O. G. (1959). Pandemonium. A paradigm for learning. The mechanics of thought processes.