Andyʼs working notes
About these notesHuman perception
Perception of form
Perception is both top/down and bottom/up
Perception is neither top-down nor bottom-up: that is, it’s not that you first process sense data then interpret it into concepts. There’s a fluid interplay between those stages, as demonstrated by images like this:


The features themselves (the strangely-shaped black markings) aren’t enough to form the interpretation. Once you have the idea that the shapes form letters, you observe the white sections as features and interpret accordingly.
Visual perception of depth
{binocular disparity}: {the difference between our two eyes’ fields of views, used to perceive depth}
Binocular disparity is mostly informative when {objects are near}, since {when objects are far, the images are almost the same}.
We get a monocular depth cue from our eye’s lens by {noticing how much adjustment is necessary to focus an object, which is related to distance}.
We get other monocular cues from interposition (one object in front of another) and from disparities in texture vs. what would be expected from linear perspective.
We can also perceive depth as we move through {motion parallax}: closer objects {move more rapidly in your field of view relative to further objects}.
(See also: Human visual system)
Unconscious inference
As objects move and change pose, and as parameters of the scene changes, we’re able to maintain remarkable constancy in our perception. Hermann von Helmholtz proposed that this is possible because we’re constantly performing unconscious inference on stimuli, for instance to determine the size of an object as a function of its size in our retina field and our perception of its distance from us. Roughly speaking, we perceive the most likely interpretation (top-down) which would produce the observe stimuli (bottom-up).
Q. What does it mean to say that size constancy may depend on an unconscious inference? Inference about what?
A. We perceive the size of objects roughly by multiplying their size on our retinal field by their estimated distance.
Q. What theory did Hermann von Helmholtz propose to explain perceptual constancy?
A. Unconscious inference: we’re constantly performing calculations combining multiple separate stimuli to form our perceptions (e.g. estimation of environment light vs. surface angle when perceiving brightness)
Recognition
Features in object recognition
One component of recognition is bottom-up processing, beginning with simple feature detection in stimuli. For instance, cells in the visual system function as feature detectors, for certain lines, angles, and motion directions.
Feature binding seems to be a key component of recognition: it takes much longer to perform a visual search for {objects with combinations of features than for those with a single feature}.
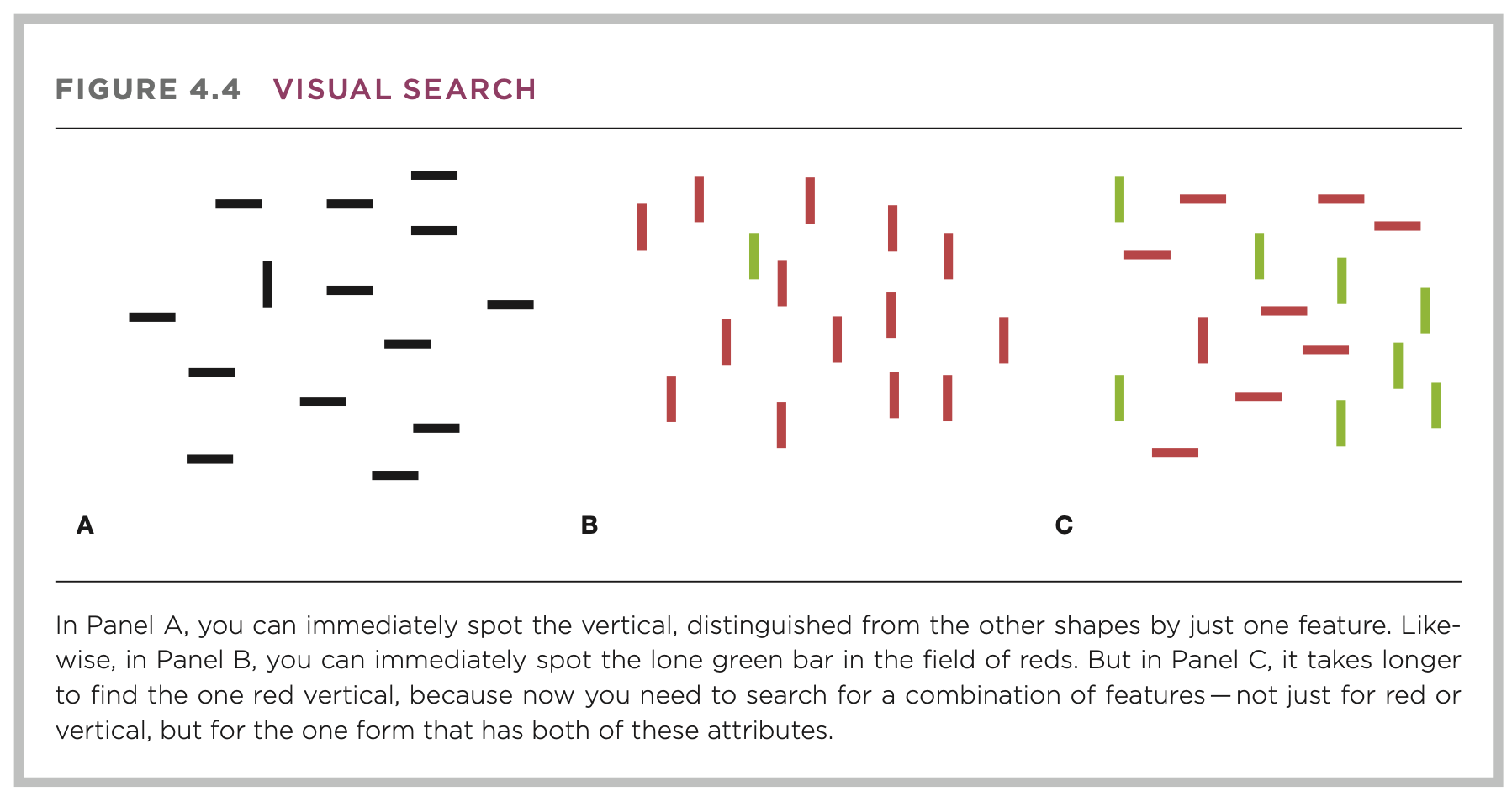
Factors affecting recognition
Cognitive scientists have studied object recognition using presentations with a Tachistoscope—e.g. to show stimuli very briefly, then asked later if various test stimuli were presented in the earlier phase. People’s ability to recognize objects presented in this way varies with a number of factors.
Jacoby and Dallas (1981) demonstrated that recognition depends on {familiarity} by {making tachistoscopic presentations of rare vs common words}; the latter were recognized about twice as often.
Jacoby and Dallas (1981) also demonstrated a {repetition priming} effect in recognition: {one group read a list of words aloud before a tachistoscopic sequence; words on that list were more likely to be recognized}.
A familiar context also seems to help, as demonstrated by the “word superiority effect”: Reicher (1969) found that if you rapidly flash a word (“fork”), then ask whether “K” or “E” was in the word, people perform better than if you had rapidly flashed just that last letter. The effect persists with fake words (“FASE”) if they’re spelling like normal English words… but not with “badly-formed” words like “FSRE”. This suggests that we’re simultaneously processing both the word and the letters, and in fact that we use our knowledge of spelling in our recognition of a word’s letters.
Q. How is the word superiority effect demonstrated?
A. Briefly flash a letter in context of a word (where another letter also forms a valid English word), then ask which of the two letters was presented. People will be more likely to answer correctly in this condition than if they were presented only the latter on its own.
Q. How does the word superiority effect demonstrate that word perception is governed by the rules of ordinary spelling?
A. The effect’s strength correlates with how “well-formed” a word is spelled—even if it’s not a real word!
One theory explaining much of this: Feature net.
Recognizing faces
We have special hardware for faces.
People with {prosopagnosia} can’t recognize individual faces.
We’re attuned to faces: we experience {pareidolia} for faces—i.e. we see faces in objects when they aren’t really there.
Q. Are faces or objects more viewpoint-dependent?
A. Faces.
We represent faces holistically, as demonstrated by {the face inversion effect}: if you {invert just the eyes and lips in a face}, it doesn’t look that strange, so long as {the face is right side up}. (Thompson, 1980)
Another finding demonstrating holistic face recognition is the {composite effect}: {when the top half of one (famous) face is combined with the bottom half of another, people have trouble recognizing the partial faces} (Young, Hellawell, and Hay, 1987).
Q. In faces, are we more sensitive to changes in configuration or changes in features?
A. Changes of configuration.
Q. In objects, are we more sensitive to changes in configuration or changes in features?
A. Changes in features.
Q. How are Feature net-based theories for face recognition unlike those of object recognition?
A. They depend on holistic perception of the overall configuration, rather than by considering features one by one and then combining.