Andyʼs working notes
About these notesBowman, S. R. (2023). Eight Things to Know about Large Language Models
A nice overview, from a technical perspective, of some empirical properties of Large language models which might be relevant to discussions of AI risk.
The eight things to know:
- LLMs predictably get more capable with increasing investment, even without targeted innovation.
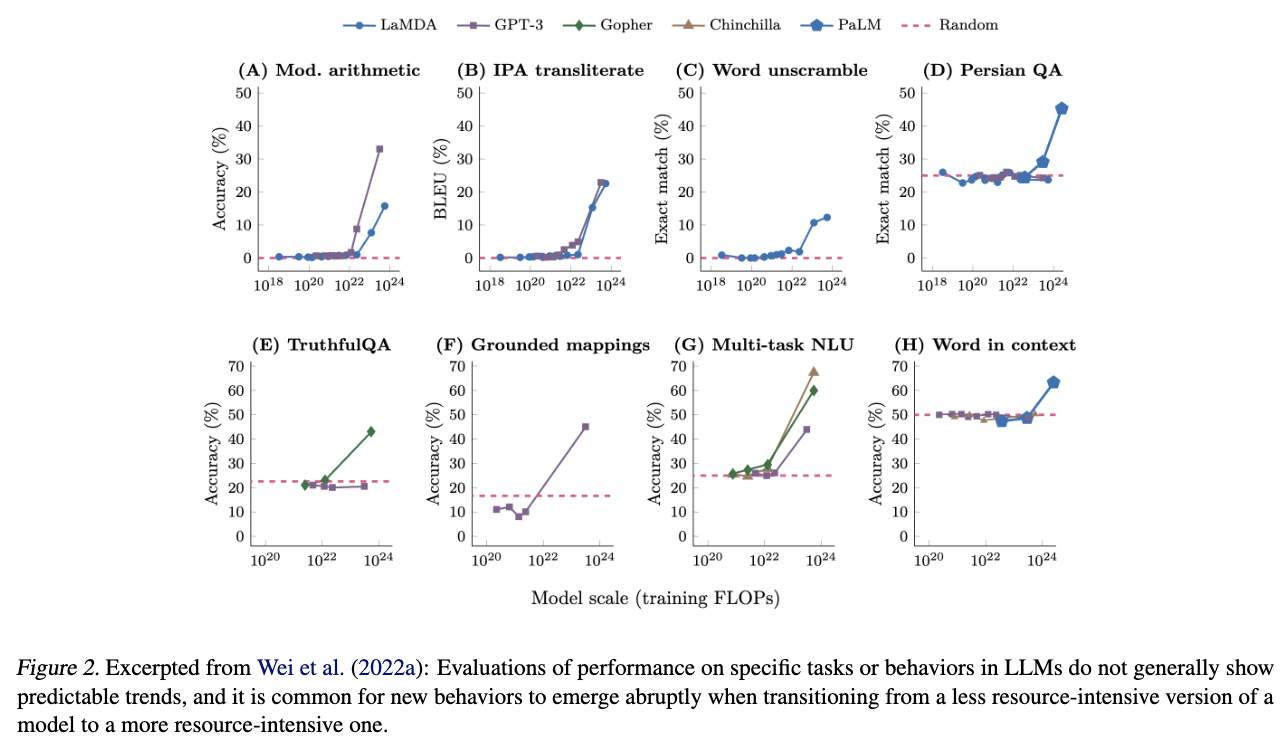
- Many important LLM behaviors emerge unpredictably as a byproduct of increasing investment.
- LLMs often appear to learn and use representations of the outside world.
- There are no reliable techniques for steering the behavior of LLMs.
- Experts are not yet able to interpret the inner workings of LLMs.
- Human performance on a task isn't an upper bound on LLM performance.
- LLMs need not express the values of their creators nor the values encoded in web text.
- Brief interactions with LLMs are often misleading.
The second is perhaps the most alarming:
Q. Example of an important GPT-3 behavior which became apparent only after its public deployment?
A. chain-of-thought reasoning
Q. Two reasons given for why LLMs can outperform humans on many tasks, despite being trained to imitate human writing?
A. 1) they see more data than any human; 2) RLHF trains them to produce useful responses without requiring demonstrations from the human first
Q. Samuel Bowman’s argument that “LLM developers inevitably have limited awareness of what capabilities an LLM has when they’re deciding whether to deploy it?”
A. “There is no known evaluation or analysis procedure that can rule out surprises like chain-of-thought reasoning in GPT-3, where users discover a way to elicit some important new behavior that the developers had not been aware of.”