Andyʼs working notes
About these notesWhen is AGI likely?
Timelines have accelerated fairly dramatically in 2022-2023. “AGI” is an essentially ambiguous term, so any speculation here must be made relative to a particular definition. Note also that this question is different from the question of when ASI is likely, though in a pessimistic fast takeoff scenario, it may not be very different. One’s answer to this question will have enormous influence over one’s fears around AI risk.
GPT-4 is a weak, slow, amnesiac AGI
First off, I’ll express a somewhat controversial take: GPT-4 is a weak, slow, amnesiac AGI. Based simply on its wide-ranging test performance, in almost all cases, if you give it a short-lived intellectual task, it will perform as well as or (often much) better than a typical well-educated teenager. To me, that’s obviously an artificial general intelligence of some kind, though of course still qualified with several meaningful asterisks.
Metaculus has stronger specific criteria for a weak AGI; see below.
Metaculus - strong AGI
https://www.metaculus.com/questions/5121/date-of-artificial-general-intelligence/
FWIW, this seems like a weak ASI to me, rather than an AGI, but whatever.
Criteria
- Able to reliably pass a 2-hour, adversarial Turing test during which the participants can send text, images, and audio files (as is done in ordinary text messaging applications) during the course of their conversation. An ‘adversarial’ Turing test is one in which the human judges are instructed to ask interesting and difficult questions, designed to advantage human participants, and to successfully unmask the computer as an impostor. A single demonstration of an AI passing such a Turing test, or one that is sufficiently similar, will be sufficient for this condition, so long as the test is well-designed to the estimation of Metaculus Admins.
- Has general robotic capabilities, of the type able to autonomously, when equipped with appropriate actuators and when given human-readable instructions, satisfactorily assemble a (or the equivalent of a) circa-2021 Ferrari 312 T4 1:8 scale automobile model . A single demonstration of this ability, or a sufficiently similar demonstration, will be considered sufficient.
- High competency at a diverse fields of expertise, as measured by achieving at least 75% accuracy in every task and 90% mean accuracy across all tasks in the Q&A dataset developed by Dan Hendrycks et al. .
- Able to get top-1 strict accuracy of at least 90.0% on interview-level problems found in the APPS benchmark introduced by Dan Hendrycks, Steven Basart et al . Top-1 accuracy is distinguished, as in the paper, from top-k accuracy in which k outputs from the model are generated, and the best output is selected.
By “unified” we mean that the system is integrated enough that it can, for example, explain its reasoning on a Q&A task, or verbally report its progress and identify objects during model assembly. (This is not really meant to be an additional capability of “introspection” so much as a provision that the system not simply be cobbled together as a set of sub-systems specialized to tasks like the above, but rather a single system applicable to many problems.)
Predictions
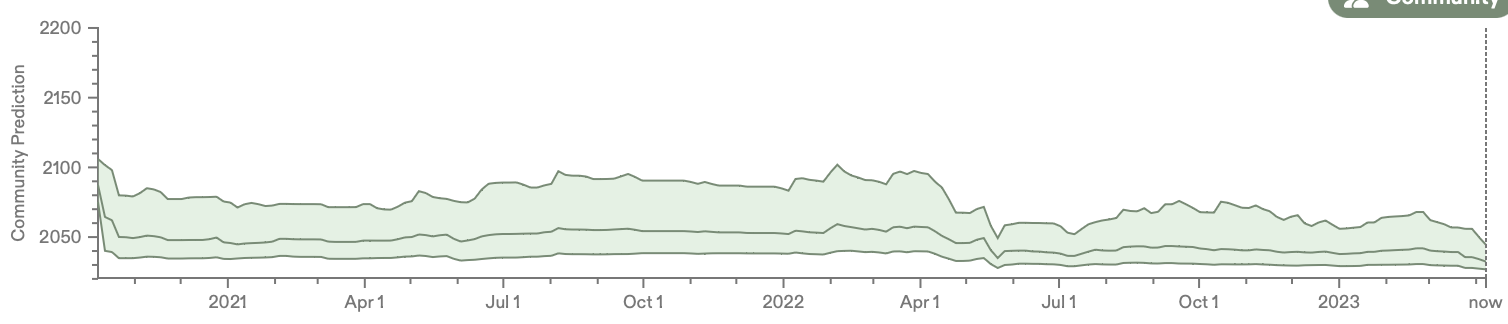
- median, 25th %ile:
- 2023-04-07: 2032, 2026
- jan 2023: 2037, ~2027
- jan 2022: 2052, ~2031
- jan 2021: 2045, ~2031
Metaculus - weak AGI
https://www.metaculus.com/questions/3479/date-weakly-general-ai-is-publicly-known/
Criteria
For these purposes we will thus define “AI system” as a single unified software system that can satisfy the following criteria, all easily completable by a typical college-educated human.
- Able to reliably pass a Turing test of the type that would win the Loebner Silver Prize .
- [This test is no longer running, but it would require that the AI answer 20 consecutive questions and that judges can’t distinguish it from a human. GPT-4 would fail this because it would divulge that it’s a bot, its personality is too obvious, and it (probably?) couldn’t keep up clarity for 20 questions. But it’s surprisingly close.]
- Able to score 90% or more on a robust version of the Winograd Schema Challenge , e.g. the “Winogrande” challenge or comparable data set for which human performance is at 90+%
- \[GPT-4 gets 87.5% on WinoGrande, evaluated 5-shot]
- Be able to score 75th percentile (as compared to the corresponding year’s human students; this was a score of 600 in 2016) on all the full mathematics section of a circa-2015-2020 standard SAT exam, using just images of the exam pages and having less than ten SAT exams as part of the training data. (Training on other corpuses of math problems is fair game as long as they are arguably distinct from SAT exams.)
- \[GPT-4 gets 89th %ile, though I think it’s being given text and images separately, rather than just an image. I don’t think that’s a real barrier, though, and I’d call this done.]
- Be able to learn the classic Atari game “Montezuma’s revenge” (based on just visual inputs and standard controls) and explore all 24 rooms based on the equivalent of less than 100 hours of real-time play (see closely-related question .)
- \[OpenAI has trained an RL system which can do this from a single human demonstration, but that’s obviously not unified here].
By “unified” we mean that the system is integrated enough that it can, for example, explain its reasoning on an SAT problem or Winograd schema question, or verbally report its progress and identify objects during videogame play. (This is not really meant to be an additional capability of “introspection” so much as a provision that the system not simply be cobbled together as a set of sub-systems specialized to tasks like the above, but rather a single system applicable to many problems.)
Predictions
- 2023-04-07: 50th, 25th %iles: June 2026, June 2024.
I’d tend towards the latter. GPT-4 is almost there. I’m pretty confident that a specially fine-tuned version could nail the first three right now. I’m not sure how to get it to realtime performance in MR—inference is currently much too slow, at least via the API. But probably within reach if run on a dedicated machine, and using just one token for controls. I don’t know how slow GPT-4’s vision is.