Andyʼs working notes
About these notesAbout these notes
Hi! I’m Andy Matuschak. You’ve stumbled upon my working notes. They’re kind of strange, so some context might help.
These notes are mostly written for myself: they’re roughly my thinking environment (Evergreen notes; My morning writing practice). But I’m sharing them publicly as an experiment (Work with the garage door up). If a note seems confusing or under-explained, it’s probably because I didn’t write it for you! Sorry—that’s sort of an essential tension of this experiment (Write notes for yourself by default, disregarding audience).
For now, there’s no index or navigational aids: you’ll need to follow a link to some starting point. You might be interested in §What’s top of mind.
👋 Andy (email, Twitter, main personal site)
PS: My work is made possible by a crowd-funded research grant from my Patreon community. You can become a member to support future work, and to read patron-only updates and previews of upcoming projects.
PS: Many people ask, so I’ll just note here: no, I haven’t made this system available for others to use. It’s still an early research environment, and Premature scaling can stunt system iteration.
Premature scaling can stunt system iteration
Particularly in Silicon Valley, when one has a prototype or an inkling that works well, the temptation is to scale it out. Make it work for more people and more use cases, turn it into a platform, make the graphs go up and to the right, etc. This is obviously a powerful playbook, but it should be deployed with careful timing because it tends to freeze the conceptual architecture of the system.
Why
General infrastructure simply takes time to build. You have to carefully design interfaces, write documentation and tests, and make sure that your systems will handle load. All of that is rival with experimentation, and not just because it takes time to build: it also makes the system much more rigid.
Once you have lots of users with lots of use cases, it’s more difficult to change anything or to pursue radical experiments. You’ve got to make sure you don’t break things for people or else carefully communicate and manage change.
Those same varied users simply consume a great deal of time day-to-day: a fault which occurs for 1% of people will present no real problem in a small prototype, but it’ll be high-priority when you have 100k users.
Once this playbook becomes the primary goal, your incentives change: your goal will naturally become making the graphs go up, rather than answering fundamental questions about your system (contra Focus on power over scale for transformative system design).
On remaining small
One huge advantage to scaling up is that you’ll get far more feedback for your Insight through making process. It’s true that Effective system design requires insights drawn from serious contexts of use, but it’s possible to create small-scale serious contexts of use which will allow you to answer many core questions about your system. Indeed: technologists often instinctively scale their systems to increase the chances that they’ll get powerful feedback from serious users, but that’s quite a stochastic approach. You can accomplish that goal by carefully structuring your prototyping process. This may be better in the end because Insight through making prefers bricolage to big design up front
Eventually, of course, you’ll need to generalize the system to answer certain questions, but at least in terms of research outcomes, it’s best to make scaling follow the need expressed by those questions. In that sense, it’s an instrumental end, not an ultimate end.
Aggressively scaling the mnemonic medium in 2020 is premature
Because Effects of the mnemonic medium on reader memory, it’s extremely tempting to scale it up. Yet the arguments described in Premature scaling can stunt system iteration suggest that platformization and generalization must be carefully timed.
In 2020, there’s plenty of demand for a more general Mnemonic medium, but there are many dangers to attempting to rapidly scale it up.
We feel confident that we don’t know what the medium wants to be. For example, we only just recently discovered that The mnemonic medium can help readers apply what they’ve learned through simple application prompts. Those experiments represent potentially enormous changes to the medium. Further, The mnemonic medium can be adapted to author an experience which unfolds over time, and we’ve barely scratched that surface.
Separately, the medium is not yet good enough. For example, it’s true that Mnemonic essays may offer detailed retention of their contents in exchange for 35-50% reading time overhead, but our small experiments have suggested that there’s a huge amount of low-hanging fruit there.
I’m building Orbit, but not with the intent to rapidly and massively scale the medium. Instead, I’m laying the foundations, trying to emphasize abstractions which won’t impede experimentation. It’s important that we scale to a small number of additional authors: their experiences will teach us much about the writer’s side of the medium.
Effects of the mnemonic medium on reader memory
- What is the causal impact of the mnemonic medium’s review sessions on reader retention?
- How efficiently can the mnemonic medium deliver reliable retention?
- To what extent do these results generalize?
The story I’d like to be able to tell:
- If you complete the review sessions, you’ll remember what you read reliably.
- … and you would remember much less without those review sessions.
- … and it won’t cost you that much time.
- … and this effect generalizes to many domains.
Within Quantum Country, we have strong evidence of 1, moderate evidence of 3, and emerging evidence of 2. We have no evidence of 4 yet.
But see also: What’s the big-picture impact of the mnemonic medium on readers?
Quantum Country user behavior
- In 2019H1, 29% of QCVC readers who finished the in-text level finished the 1 month level
- As of 2020Q1, several hundred users have demonstrated 1+ month of retention for QCVC
Reader perceptions
- “I’ve only done your first quantum country course (so far) but I find it remarkable that I can view the proof and follow it, knowing what everything means. It’s almost like Neo in The Matrix telling Morpheus, ‘I know quantum computing’” source
- “Doing the review sessions gives me what it promises to do, I guess. It is the confidence that I will remember the material and will be able to juggle the facts effortlessly. Although I already had a little prior experience with quantum computing, I benefited from the essays a lot. It went smooth and solidified my knowledge which was previously quite shaky and had too much white spots before. I’m very grateful for this mnemonic essays experiment existence.” — Dmitry Urbanovich Re: Hello from Quantum Country!
- “Unlike other ways to learn, I am not worried about forgetting what I
learned in the future, because I know there’s someone who will always
remind me to review the key parts at the right time points. And it’s
not just a feeling. According to the result of reviewing, I think I do
have memorized most of them reliably.” — Kevin
Quantum Country readers reliably develop detailed retention for embedded questions
Late-2019 schedule
For late-2019 schedule data, see After five repetitions, most Quantum Country readers reach at least 1 month of demonstrated retention for at least 95% of questions
See also Quantum Country users rarely forget after demonstrating five-day retention
Early-2019 schedule
All this data is among readers who answered 80%+ of QCVC questions in the essay before their first review session.
After 6 repetitions (using an earlier, less aggressive SRS schedule), most 2019H1 users average about 54 days of retention per question.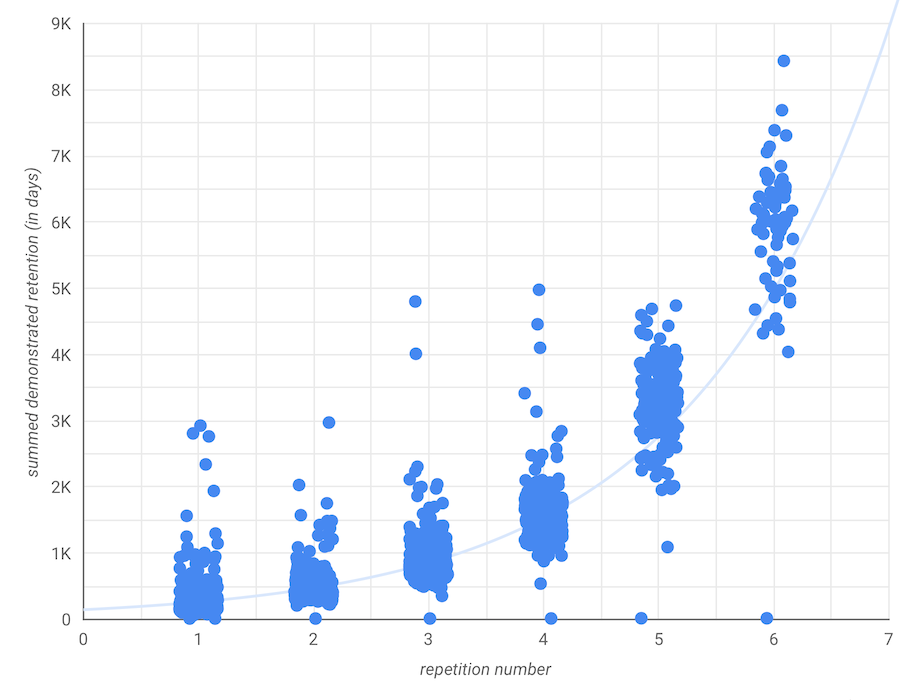
The median 2019H2 reader had demonstrated 2-week retention on 95%+ of QCVC prompts by session 9. Source These users average about 24 days of retention per question after 3 repetitions of every prompt. We don’t have data on later repetition numbers yet.
But is this just a survivorship effect? Would these readers have developed this retention in any case? Or is it a selection effect—did these readers already have detailed retention of this material? What is the causal impact of the mnemonic medium’s review sessions on reader retention?